
2024
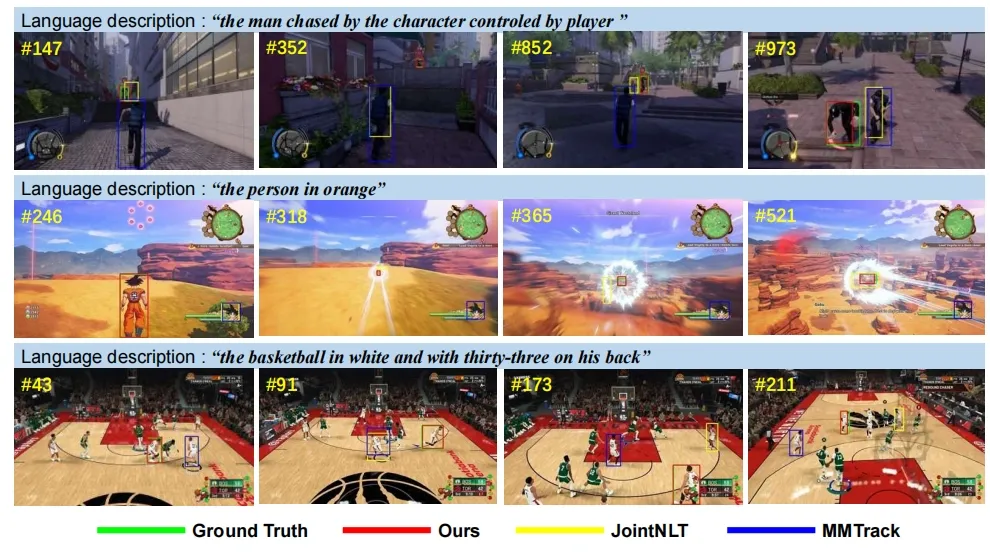
MemVLT: Visual-Language Tracking with Adaptive Memory-based Prompts.
Conference on Neural Information Processing Systems (NeurIPS), 2024.
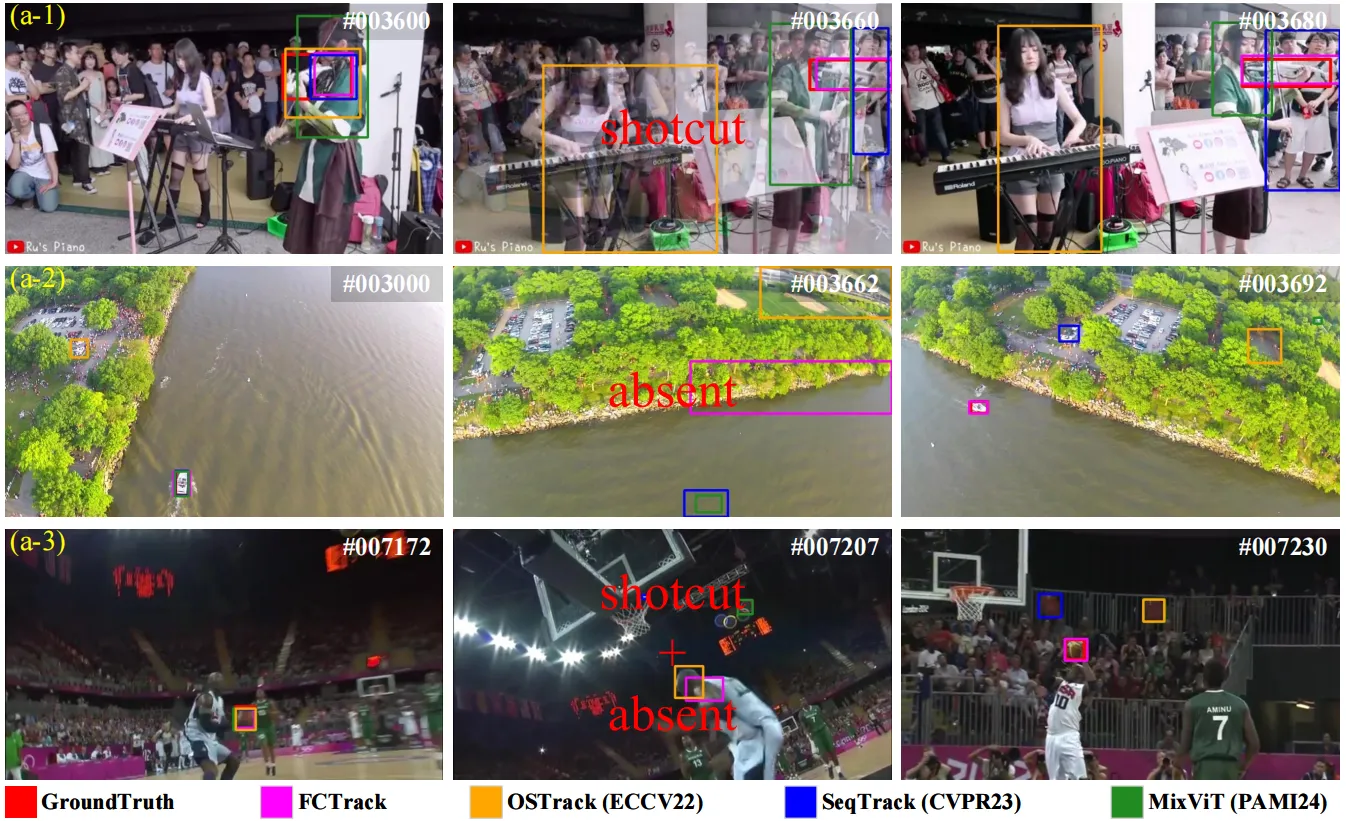
Beyond Accuracy: Tracking more like Human through Visual Search.
Conference on Neural Information Processing Systems (NeurIPS), 2024.

DTLLM-VLT: Diverse Text Generation for Visual Language Tracking Based on LLM.
CVPR Workshop on Vision Datasets Understanding (CVPRW, Oral, Best
Paper Honorable Mention Award), 2024.
2023

Visual Intelligence Evaluation Techniques for Single Object Tracking: A
Survey (单目标跟踪中的视觉智能评估技术综述)
Journal of Images and Graphics (《中国图象图形学报》, CCF-B Chinese Journal), 2023

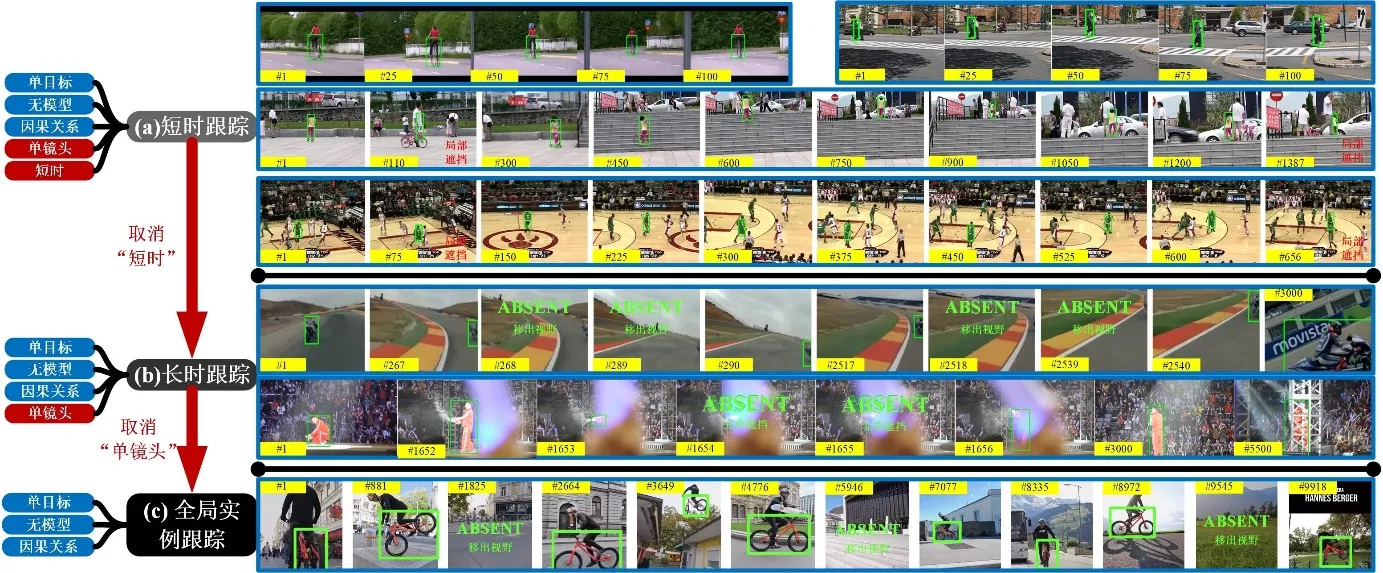
A Multi-modal Global Instance Tracking Benchmark (MGIT): Better Locating Target
in Complex Spatio-temporal and Causal Relationship.
Conference on Neural Information Processing Systems (NeurIPS), 2023.
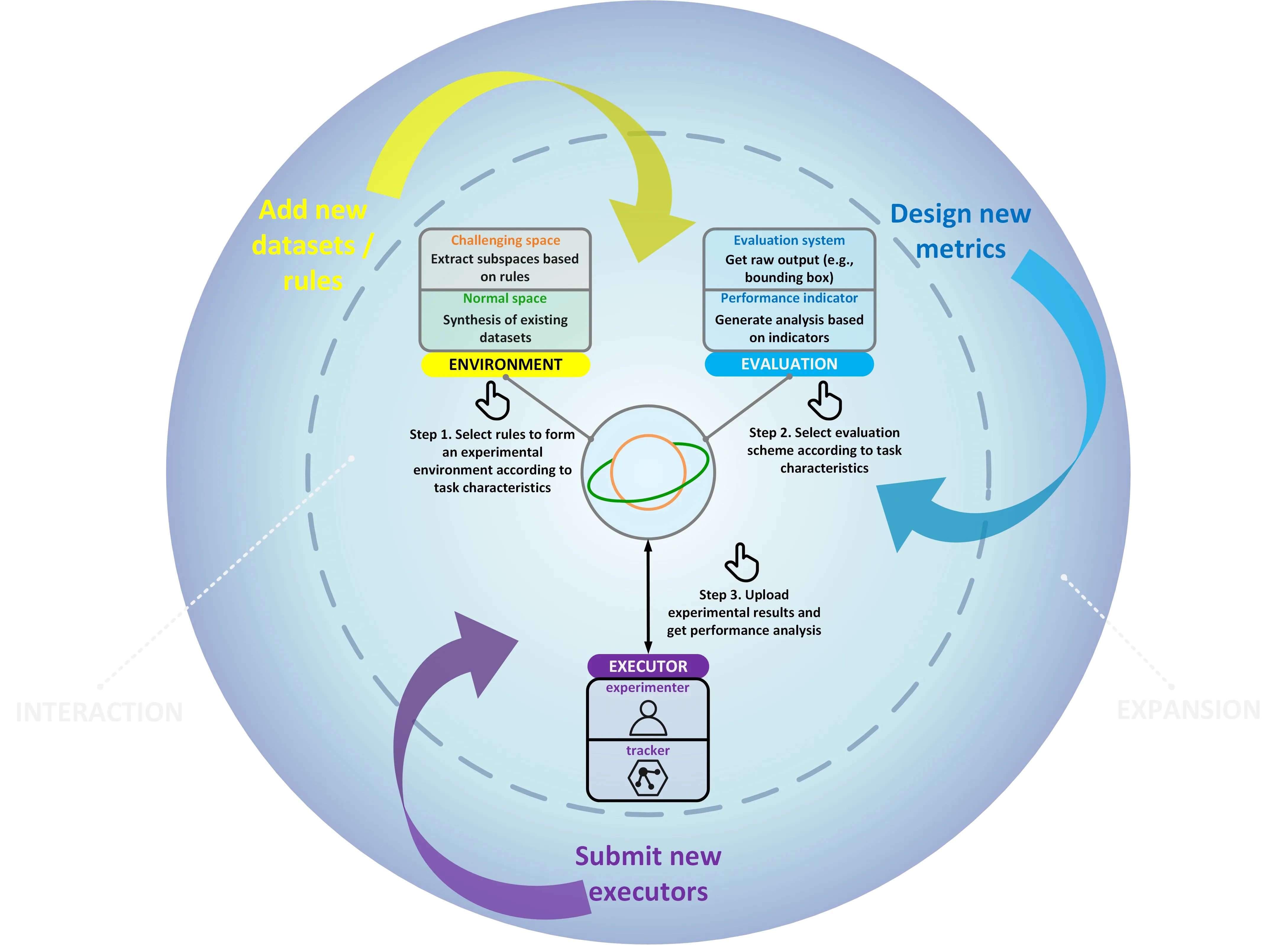
SOTVerse: A User-defined Task Space of Single Object Tracking.
International Journal of Computer Vision (IJCV), 2023.
2022

Global Instance Tracking: Locating Target more like Humans.
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI),
2022.

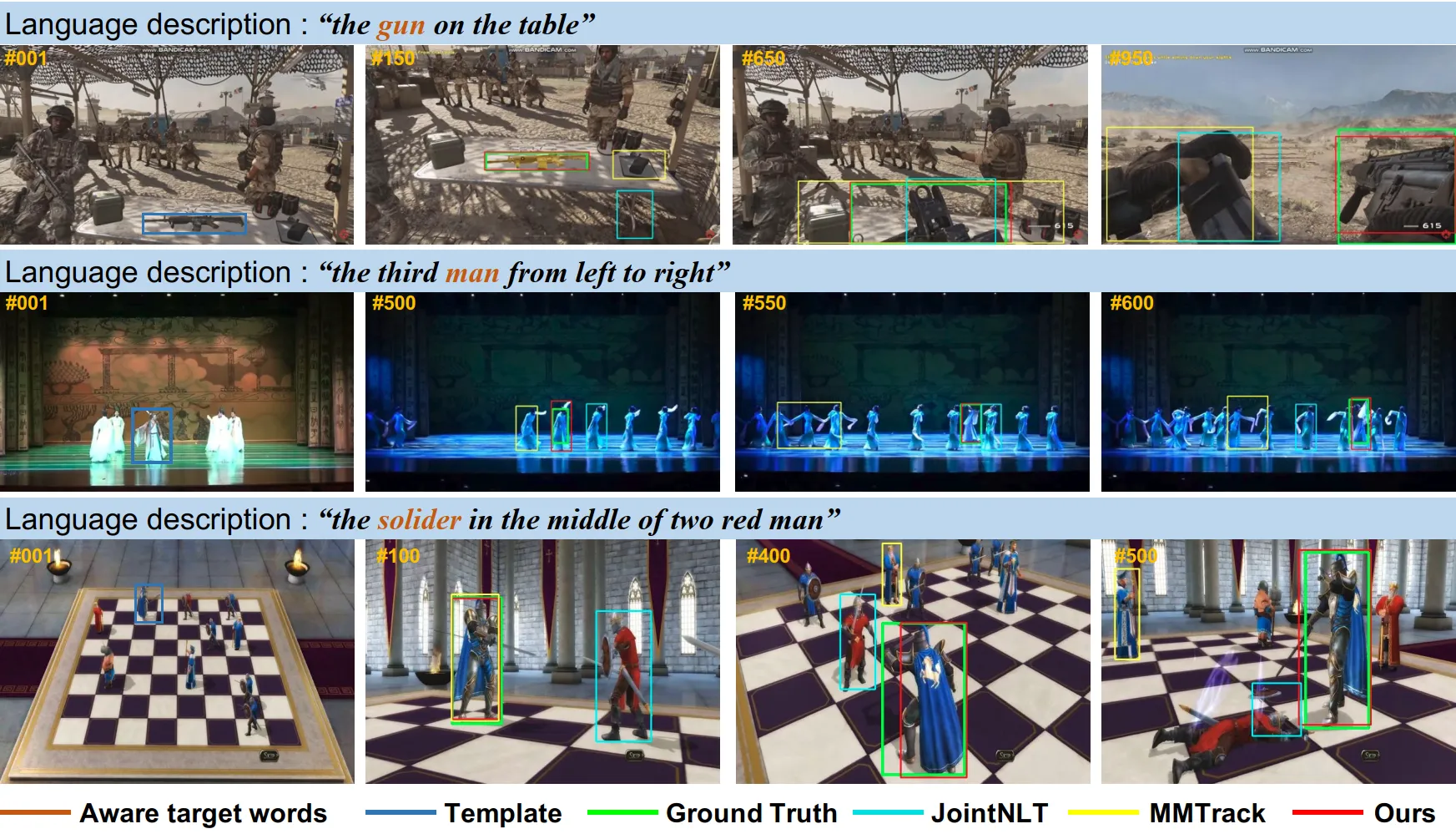
Robust Vision-Language Tracking through Multimodal Target-Context Cues Aligned with
Target States.
Submitted to a CCF-A conference, 2024.
DTVLT: A Multi-modal Diverse Text Benchmark for Visual Language Tracking Based on LLM.
Submitted to a CAAI-A conference, 2024.

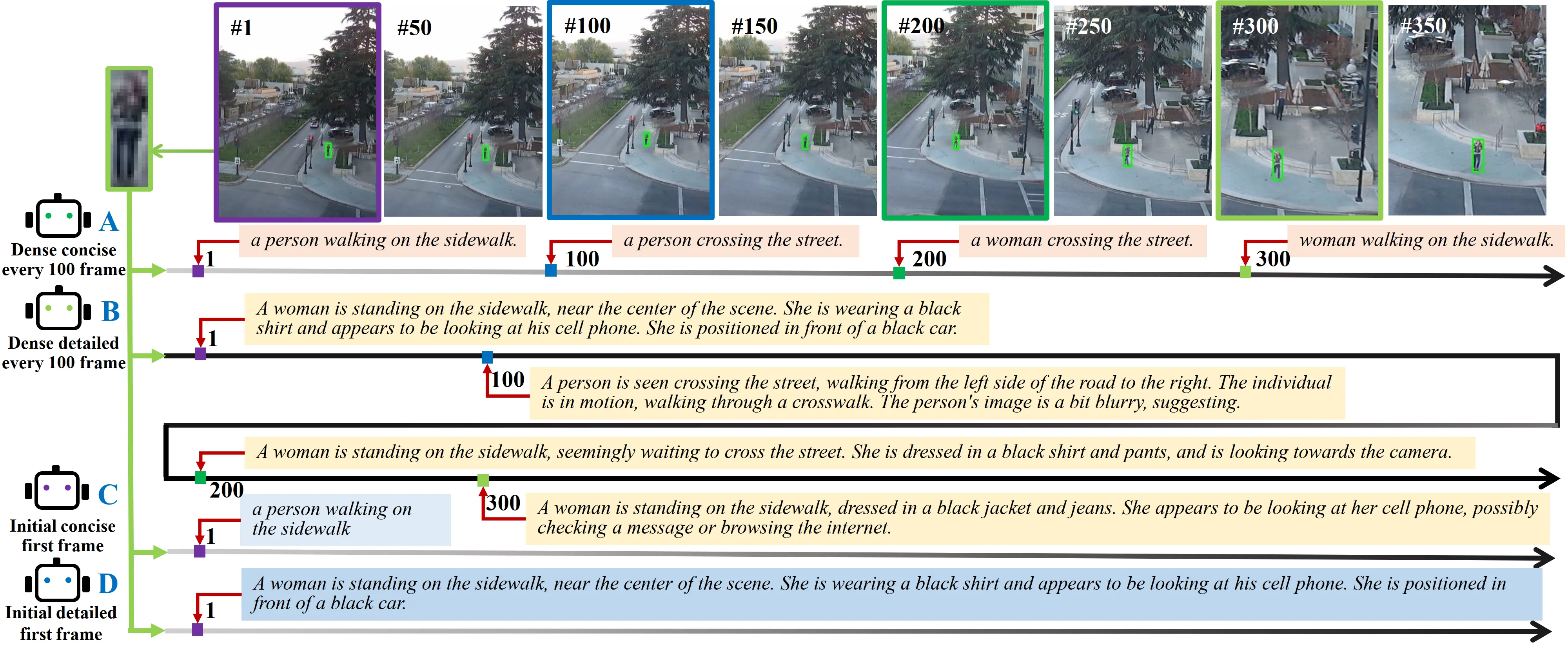
Can LVLMs Describe Videos like Humans? A Five-in-One Video Annotations Benchmark for
Better Human-Machine Comparison.
Submitted to a CAAI-A conference, 2024.

Enhancing Vision-Language Tracking by Effectively Converting Textual Cues into Visual
Cues.
Submitted to a CCF-B conference, 2024.
